N-grama
| ||||||

N-grama. En Inteligencia Artificial, procesamiento de lenguaje natural, Bioinformática, recuperación de información se llama n-grama a una subsecuencia de n elementos consecutivos en una secuencia dada. Si n=2 se denominan bigramas; n=3, trigramas; para n>=4 entonces se llaman genéricamente n-gramas o Modelos de Markov de orden (n-1).
Los n-gramas son de gran utilidad en el tratamiento de textos, la determinación del lenguaje de documentos, el procesamiento estadístico de los mismos o el descubrimiento o predicción de genes en tanto estos son subsecuencias dadas dentro del material genético.
Sumario
Definición
Sea una secuencia S de elementos ordenados s1s2s3...sk... se denomina n-grama a cualquier subsecuencia A=si+1si+2...si+n, donde i es un valor entre 0 y |S|-n para garantizar que la longitud de A sea siempre n o lo que es lo mismo |A|=n; n>1.
Los casos particulares n=2, n=3 reciben los nombres de bigramas y trigramas respectivamente.
Como datos adicionales, la definición abarca el caso particular de un n-grama, pero en la práctica es preferible pensarlo como el conjunto de los mismos que componen la secuencia dada.
Ejemplos
Dado el texto "Platero y yo", si se toma como elementos los caracteres que lo componen, sus trigramas serían: "Pla", "lat", "ate", "ter", "ero", "ro ", "o y", " y ", "y y" y finalmente " yo".
Para el caso de "El horizonte es límite de lo que podemos ver", si se establecen como elementos a las palabras del texto, sus bigramas son: "El horizonte", "horizonte es", "es límite", "límite de", "de lo", "lo que", "que podemos", "podemos ver".
Nota: En el caso del tratamiento de texto suelen depurarse los signos de puntuación y otras veces también los espacios en blanco entre las palabras.
Antecedentes históricos
Según la Teoría Matemática de la Información de Claude E. Shannon en un determinado lenguaje L derivado de un alfabeto A, cada secuencia lingüística w=s1s2...sn-1 donde si es un símbolo del alfabeto, determina para cada símbolo aj de A una probabilidad P(aj) de ser el próximo elemento sn de w, de manera que ![]() , donde las probabilidades P(aj) son calculadas por acumulación histórica. En conclusión, los símbolos anteriores en una frase deben determinar la aparición más probable de un grupo de símbolos sobre los otros del alfabeto. Esta idea es la base de los modelos de n-gramas.
, donde las probabilidades P(aj) son calculadas por acumulación histórica. En conclusión, los símbolos anteriores en una frase deben determinar la aparición más probable de un grupo de símbolos sobre los otros del alfabeto. Esta idea es la base de los modelos de n-gramas.
También hay elementos de los mismos en las cadenas de Markov que alcanzaron un gran nivel de formalización matemática y probabilística, consiguiendo que las mismas tuvieran gran aplicación en diversos ámbitos hasta la actualidad.
Aplicación
El campo de aplicación de los n-gramas es muy variado: tratamiento estadístico de lenguaje natural tanto escrito como visual o sonoro, de patrones, en análisis de imágenes, predicción de genes y formación de proteínas en bioinformática.
Estimación del idioma de documentos.
Uno de los usos más interesante es el de buscar la similitud entre un documento y un grupo de documentos. Este hecho cobra una gran importancia en la estimación del idioma predominante en el texto.
Supóngase que se tienen dos conjuntos de trigramas I1 e I2, asociados a los idiomas inglés y español, provenientes de trigramizar grandes volúmenes de textos en uno y otro idioma, para que I1 e I2 sean representativos. Luego se tienen el conjunto de trigramas T de un documento que podría estar escrito en inglés o español. Puede estimarse el idioma predominante mediante la expresión de evaluación de semenjanza:
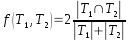 donde T1 y T2 son conjuntos de trigramas y
donde T1 y T2 son conjuntos de trigramas y  .
.
Se calculan f(T,I1)=t1 y f(T,I2)=t2 y si t1 > t2 el documento asociado a T está escrito en inglés, de lo contrario en español. En caso de t1=t2 no puede decidirse.
De manera más general, si se tuvieran los trigramas I1, I2, ..., In asociados a los idiomas l1, l2, ... , ln y los valores de semenjanza f(T,I1), f(T,I2), ..., f(T,In), se decide el idioma del texto asociado a los trigramas T por el valor mayor de los f(T,Ii), si hubiera más de uno no puede decidirse.
Fuentes
- Christopher D. Manning, Hinrich Schütze. Foundations of Statistical Natural Language Processing. MIT Press, 1999.
- Michael Collins. A new statistical parser based on bigram lexical dependencies. In Proceedings of the 34th Annual Meeting of the Association of Computational Linguistics, Santa Cruz, CA. 1996. Págs 184-191.
- Jhonlier Suárez Molina. Spider UCI. Tesis de Licenciatura en Ciencias de la computación. UH, UO, UCI. La Habana 2004. Pág 46.
- Artículo N-grama Disponible en: "es.wikipedia.org" Consultado: 23 de enero de 2012