Elasticsearch
| ||||||||||||||||

Elasticsearch. Es un motor de búsqueda en tiempo real y de analítica. Permite explorar datos a una velocidad y a una escala que antes no era posible. Se utiliza para búsqueda de texto completo, búsquedas estructuradas, analítica en tiempo real, o una combinación de las tres.
Historia
Hace años Shay Bannon hizo un viaje con su esposa a Londres, donde ella estaba estudiando para ser chef. Mientras buscaba un empleo, empezó a jugar con las primeras versiones de Lucene (interfaz de programación de aplicaciones), con la intención de construir un motor de búsqueda de recetas para ella.
Trabajar con esta inerfaz puede ser complicado así que Shay comenzó a trabajar en una capa de abstración que facilitaría a los programadores en Java a realizar búsquedas en sus aplicaciones. Lanzó su primer proyecto open-source llamado Compass. Cuando pasado un tiempo encontró trabajo en un entorno de alto rendimiento distribuido con procesamiento en memoria así que decidió reescribir Compass y llamarlo Elasticsearch.
Características
- Motor de búsqueda OpenSource
- Escrito en Java
- Basado en Apache Lucene
- Permite Arquitectura: distribuida, escalable, en alta disponibilidad
- Capacidades de búsqueda y análisis en tiempo real mediante peticiones GET
- Útil para soluciones NoSQL (sin transacciones distribuidas)
- Permite utilizarlo sobre el ecosistema Hadoop para proyectos de BigData
- API RESTfull sobre http para consulta, indexación, administración en diferentes lenguajes
- Permite múltiples índices en un cluster, así como alias de índices
- Permite consultas sobre uno o varios índices
- Full Text Search o búsqueda por texto completo
- Indexa todos los campos de los documentos JSON (sin esquema rígido)
- Búsquedas mediante ElasticSearch Query DSL (Domain Specific Language): multilenguaje, geolocalización, contextual, autocompletar, etc
Uso
A diferencia de otros motores de búsqueda y recuperación de información, ElasticSearch actúa como repositorio de información, almacenando los documentos que indexa. Esto permite reemplazar almacenes de documentos como MongoDB o Raven DB por ElasticSearch en los proyectos, si se considera necesario.
Tanto MongoDB como ElasticSearch son repositorios de documentos desnormalizados en los que los documentos que gestionan no necesitan disponer de un esquema rígido para poderlos introducir en el sistema. Las Bases de Datos relacionales (SQL) requieren definir las tablas, o esquema de la información, antes de poder introducir registros de datos. Esto hace que se tenga que pensar muy bien la estructura de la información antes de comenzar a programar en un proyecto para evitar que se produzcan cambios, puesto que estos cambios representarían una migración de los datos a otro esquema o tenerlos que adaptar. Si disponemos de un volumen de datos muy grande, estaríamos hablando de un proceso muy lento y costoso.
Sin embargo, como ElasticSearch no requiere un esquema predefinido de los datos, la misma colección de documentos puede contener documentos de estructura diferente, permitiendo un desarrollo más ágil.
Por otro lado, los documentos almacenados en ElasticSearch están en formato JSON que son estructuras de datos más cercanas a las entidades que se manejan a nivel de negocio. Esto también facilita un desarrollo más ágil ya que el propio documento contiene todos los elementos de la entidad de negocio sin tener la necesidad de lanzar consultas complejas sobre una base de datos para obtenerlos y poderlos procesar posteriormente. Por otro lado, mediante su RESTful API este motor de búsqueda será ideal para realizar cualquier integración con otras tecnologías en nuestro proyecto.
Arquitectura
La topología de cluster para Elastic puedes ser la de la siguiente figura. Tenemos un índice de Elasticsearch con dos shards, replicado a traves de los nodos en dos “zonas” diferentes para aumentar la disponiblidad, con un solo master para las tres zonas. También tenemos dos nodos de cliente que mandaran peticiones.
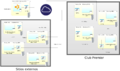
Arquitectura Elasticsearch
